| Trong bài “phương pháp xử lý giá trị missing
trong stata” kì trước được trình bày trong mục “Phương pháp luận/quản
lý, xử lý số liệu”, thongke.info đã giới thiệu 2 phương pháp xử lý
giá trị missing: kiểm tra giá trị
thực và thay thế giá trị missing và thay thế giá trị missing bằng
các giá trị trung bình, trung vị.
Trong bài này, thongke.info giới thiệu với
các bạn phương pháp dự đoán/ước tính giá trị missing – IMPUTATION dựa
trên mô hình phân tích hồi quy đa biến, sử dụng phương pháp Multiple
Imputation – MI trong Stata.
Chúng ta sẽ xem xét ví dụ: một chương
trình can thiệp có mục tiêu nâng cao kiến thức phòng tránh HIV cho
thanh thiếu niên đường phố. Chương trình thực hiện nghiên cứu tìm hiểu
các yếu tố tác động đến kiến thức về HIV của thanh thiếu niên đường
phố.
Chúng ta xem xét data file bằng lệnh mô tả:
Trong data file ở trên,
biến total_kn là tổng điểm kiến
thức của thanh thiếu niên về phòng tránh HIV.
Nghiên cứu viên muốn chạy
mô hình hồi quy tuyến tính để tìm hiểu mối liên quan giữa tổng điểm
kiến thức của thanh thiếu niên về phòng tránh HIV với các biến độc
lập: tuổi, học vấn, và có tham gia vào hoạt động của các dự án
truyền thông về HIV.
Mô hình tuyến tính sẽ chạy trong stata như sau:
regress total_kn
c1 educ2 educ3
ex_proje
Tuy
nhiên, chúng ta thấy có 7 trường hợp biến
phụ thuộc total_kn không có giá trị
(missing). Lệnh codebook dưới đây:
Codebook
total_kn
Chúng
ta quyết định sử dụng phương pháp Multiple Imputation trong Stata– (tạm
dịch ước tính giá trị missing nhiều lần dựa trên các giá trị khác)
Ở ví dụ này, qua các phân tích đã thực
hiện, nhóm nghiên cứu thấy rằng biến total_kn là tổng điểm kiến thức của thanh thiếu
niên về phòng tránh HIV có mối tương quan có ý nghĩa thống kê với
các biến: tuổi, học vấn, và có tham gia vào hoạt động của các dự án
truyền thông về HIV.
Hay nói một cách khác, dựa
trên tập hợp giá trị của các biến này (qua mô hình phân tích hồi
quy) chúng ta có thể ước đoán được giá trị của total_kn là tổng điểm kiến thức của thanh thiếu
niên về phòng tránh HIV.
Chúng ta thực hiện các
bước sử dụng phương pháp MI trong Stata (Chú
ý: Luận thuyết sử dụng MI không yêu cầu missing data ở dưới dạng nào,
ví dụ MCAR – missing completely at random)
Bước
1: set data về dạng mi data
mi set mlong
Bước 2: đăng kí các biến dùng để ước tính: bao
gồm cả biến phụ thuộc và độc lập sử dụng lệnh mi
register
mi
register imputed total_kn mi
register regular c1 educ2 educ3 ex_proje
Bước 3: Sử dụng mô hình hồi quy tuyến tính để ước
tính giá trị missing cho biến phụ thuộc total_kn sử dụng lệnh mi
impute regress
mi
impute regress total_kn c1
educ2 educ3 ex_proje, add(20) Ở lệnh trên chúng ta
dùng add(20) có nghĩa là chúng ta yêu cầu stata ước tính 20 lần giá
trị của biến total_kn missing (chính vì thế gọi là multiple imputation)
Nhìn vào bảng kết quả,
chúng ta thấy 7 giá trị missing của total_kn đã được ước tính –
imputed
Bây giờ chúng ta có thể chạy mô hình hồi quy
tuyến tính với biến total_kn đã được imputed, sử dụng lệnh mi estimate
mi
estimate, dots: regress total_kn c1
educ2 educ3 ex_proje
Chú ý: Các hình ảnh output (kết quả) trong bài viết chỉ mang tính minh họa. Nguyễn Trương Nam - Thongke.info
Số lượt đọc:
3507
-
Cập nhật lần cuối:
23/08/2012 04:54:39 PM Hướng dẫn khôi phục dữ liệu sau khi gặp sự cố "corrupted"27/01/2013 11:11' PM Khi các bạn đang nhập liệu, nguồn của máy tính đột ngột bị mất (do lỏng đường dây, do mất điện đột ngột) mà bạn vẫn chưa kip lưu thì sau khi bạn khởi động lại máy tính và mở form epidata đang nhập liệu, máy tính sẽ báo lỗi như sau “One or more records are corrupted”.
Các bạn sẽ cố gắng tìm mọi cách để mở file đó ra, nhưng sẽ không thể mở được trực tiếp bằng phần mềm Epidata. Như vậy các bạn sẽ phải nhập lại toàn bộ số phiếu mình đã nhập trong form đó nếu bạn không có file backup.
Thongke.info xin giới thiệu với các bạn một cách rất đơn giản để khắc phục sự cố này. Thống kê và phương pháp phân tích số liệu - Sử dụng Stata12/01/2013 10:09' AM Xin chào các bạn, Xin chào các bạn,
- Khái niệm về thống kê cơ bản
- Lựa chọn trắc nghiệm thống kê
- Thực hành thống kê với Stata
Bảng thuật ngữ Dịch tễ học và Thống kê14/11/2012 11:49' AM Xin chào các bạn, Trong quá trình học tập và làm việc liên quan tới Dịch tễ học và Thống kê chắc hẳn các bạn đã từng được nghe hoặc biết đến các thuật ngữ như: Case-control Study, Cohort Study, Cross-sectional Study, Chi Square, Crude odds ratio, vv. Hay các thuật ngữ đươc viết tắt: OR, RR, EFp, EFe, vv. Hiện nay có nhiều thuật ngữ được dịch khác nhau dựa trên những quan điểm nhìn nhận khác nhau của các nhà Dịch tế và Thống kê học. Thongke.info xin giới thiệu bảng thuật ngữ Dịch tễ học và Thống kê trên quan điểm của thongke.info. Những vấn đề cơ bản của thống kê thực hành30/10/2012 09:58' AM Thống kê thực hành không nhằm mục đích vào giải quyết những vấn đề lý thuyết của thống kê và thống kê toán. Thống kê thực hành bao gồm các nội dung của quá trình nghiên cứu thống kê cụ thể. Các nội dung này được tiếp cận nhất quán trên tư tưởng của thống kê toán, đặc biệt là phương pháp mẫu ngẫu nhiên trong nghiên cứu thống kê cũng như các công cụ cần thiết trong thực hành, nghiên cứu thống kê. Với mục đích nói trên, thống kê thực hành đề cập đến những nội dung cụ thể sau: Thống kê thực hành không nhằm mục đích vào giải quyết những vấn đề lý thuyết của thống kê và thống kê toán. Thống kê thực hành bao gồm các nội dung của quá trình nghiên cứu thống kê cụ thể. Các nội dung này được tiếp cận nhất quán trên tư tưởng của thống kê toán, đặc biệt là phương pháp mẫu ngẫu nhiên trong nghiên cứu thống kê cũng như các công cụ cần thiết trong thực hành, nghiên cứu thống kê. Với mục đích nói trên, thống kê thực hành đề cập đến những nội dung cụ thể sau: Thống kê mô tả26/10/2012 09:46' PM Thống kê mô tả luôn là cách thức mở đầu cho các phân tích thống kê nói chung và phân tích kinh tế xã hội nói riêng. Có nhiều cách hiểu và đánh giá vai trò của thống kê mô tả, với quan niệm thống kê mô tả là bước khai phá số liệu, các nội dung trong chương này trình bày thống kê mô tả với hai mục đích chính: một là, thống kê mô tả như một cách thức tổng hợp số liệu và mô tả các đặc trưng quan trọng của các biến; hai là, dùng thống kê mô tả phát hiện các đặc trưng và quan hệ tiềm ẩn trong tổng thể, đặc biệt là các quan hệ nhiều biến. Thống kê mô tả luôn là cách thức mở đầu cho các phân tích thống kê nói chung và phân tích kinh tế xã hội nói riêng. Có nhiều cách hiểu và đánh giá vai trò của thống kê mô tả, với quan niệm thống kê mô tả là bước khai phá số liệu, các nội dung trong chương này trình bày thống kê mô tả với hai mục đích chính: một là, thống kê mô tả như một cách thức tổng hợp số liệu và mô tả các đặc trưng quan trọng của các biến; hai là, dùng thống kê mô tả phát hiện các đặc trưng và quan hệ tiềm ẩn trong tổng thể, đặc biệt là các quan hệ nhiều biến.
Thongke.info xin giới thiệu với các bạn bài viết: thống kê mô tả, các bạn có thể download bài viết tại đây.
Thongke.info xin cám ơn PGS.TS Ngô Văn Thứ đã chia sẻ bài viết.
Phương pháp kiểm định tương tác trong phân tích số liệu nghiên cứu khoa học - Assessment of Interaction02/08/2012 09:36' AM Giới
thiệu
Đôi
khi, mối liên quan giữa hai biến bị thay đổi bởi một biến Bài đã đăng: Chuyển biến dạng chữ có chứa ngày tháng sang biến dạng ngày tháng trong Stata26/07/2012 08:19' PM Ngày tháng năm (date) là một trong các dạng biến đặc biệt và quan trọng trong quá trình phân tích số liệu, nhất là trong các điều tra dinh dưỡng vì liên quan đến tuổi của bà mẹ, tuổi của trẻ nhỏ. Tuy nhiên trong quá trình thu thập số liệu hay nhập liệu thì biến ngày tháng đã không được định dạng đúng về dạng ngày tháng (date) mà lại ở dạng chữ (string) hay dạng số (numberic) do đó chúng ta không thể tính tuổi của ĐTNC (bà mẹ, trẻ nhỏ) hay những giá trị khác liên quan đến biến ngày tháng được. Phần này thongke.info xin giới thiệu tới các bạn cách để chuyển biến dạng chữ (String variable) có chứa ngày tháng năm sang dạng ngày tháng năm chuẩn (date) trong stata. Ngày tháng năm (date) là một trong các dạng biến đặc biệt và quan trọng trong quá trình phân tích số liệu, nhất là trong các điều tra dinh dưỡng vì liên quan đến tuổi của bà mẹ, tuổi của trẻ nhỏ. Tuy nhiên trong quá trình thu thập số liệu hay nhập liệu thì biến ngày tháng đã không được định dạng đúng về dạng ngày tháng (date) mà lại ở dạng chữ (string) hay dạng số (numberic) do đó chúng ta không thể tính tuổi của ĐTNC (bà mẹ, trẻ nhỏ) hay những giá trị khác liên quan đến biến ngày tháng được. Phần này thongke.info xin giới thiệu tới các bạn cách để chuyển biến dạng chữ (String variable) có chứa ngày tháng năm sang dạng ngày tháng năm chuẩn (date) trong stata.
Trường hợp 1: Biến ngày tháng dạng chữ (string variable có chứa 4 chữ cho trường năm, ví dụ 2007)
Ví dụ: biến date với format dạng chữ, có chứa số liệu ngày tháng như sau: Kiểm tra mối tương quan giữa các biến bằng phương pháp vẽ biểu đồ và kiểm định sử dụng STATA25/07/2012 01:24' PM Trong phân tích số liệu và thống kê học, phân tích tương quan là một cách để đo lường mối liên quan giữa hai hay nhiều biến với nhau. Trong nghiên cứu khoa học chúng ta thường dựa vào mối liên quan giữa các biến để tính toán và dự báo sự thay đổi của một biến dựa vào thông tin mà chúng ta biết được về các biến liên quan đó. Ví dụ như dựa vào mối tương quan giữa thu nhập và giáo dục, chúng ta có thể thấy những người có trình độ học vấn cao hơn sẽ có thu nhập cao hơn. Khi chúng ta biết được trình độ học vấn của một người, ta có thể dự đoán được thu nhập trong tương lai của họ.
Trong bài này, thongke.info sẽ giới thiệu cụ thể mối tương quan giữa hai biến bằng các phương pháp vẽ đồ thị và sử dụng các hệ số tương quan sử dụng phần mềm Stata. Hướng dẫn sử dụng lệnh relate trong Epidata để kết nối các file dữ liệu có cùng một mã ID11/07/2012 05:35' PM Hướng dẫn
sử dụng lệnh relate trong Epidata để kết nối các file dữ liệu có cùng
một mã ID (ứng dụng trong điều tra nhân khẩu hộ gia đình).
Phần trước thongke.info đã giới thiệu tới các
bạn cách tạo form nhập liệu, cách viết lệnh consistency check trong Epidata. Phần
này thongke.info xin được giới thiệu tới các bạn lệnh relate trong Epidata.
Chúng ta sử dụng lệnh relate khi các bạn có
các rec file riêng biệt và muốn link các rec file đó lại với nhau với cùng một
mã ID.
Ví dụ: Khi
các bạn có một điều tra nhân khẩu hộ gia đình với mục tiêu là điều tra thông
tin chung của hộ gia đình, thông tin về từng thành viên trong gia đình. Phương pháp xử lý giá trị missing trong Stata05/07/2012 03:45' PM Trong quá trình thu thập số liệu, nhập liệu có những biến sẽ có giá trị missing. Nguyên nhân có thể do phỏng vấn viên quên hỏi, do nhập liệu viên nhập sót hoặc do thiết kế bộ câu hỏi có những câu hỏi chỉ dành riêng cho nhóm đối tượng nào đó. Ví dụ như hỏi về việc chăm sóc thai nghén sẽ chỉ hỏi ở những người phụ nữ đã từng mang thai, hay hỏi về sử dụng dịch vụ y tế trong 1 tháng qua thì sẽ chỉ hỏi với những đối tượng đã đến cơ sở y tế 1 tháng qua… Chúng ta cần phát hiện và xử lý các giá trị missing này để đảm bảo tính chính xác của các kết quả phân tích. a. Phát hiện các giá trị missing Quản lý số liệu17/06/2012 10:46' AM Thongke.info xin giới thiệu với các bạn bài viết về quản lý số liệu, trong bài viết sẽ cung cấp nhưng phương pháp: thiết kế bộ câu hỏi thu thập số liệu, thử nghiệm bộ câu hỏi trước khi nhập liệu, tạo bộ câu hỏi (.Ques, .Rec, .Chk), nhập số liệu (nhập hai lần), kiểm tra số liệu, kiểm tra logic và tính nhất quán của bộ số liệu, làm sạch số liệu (frequency, cross-tabs, bảng phân bố), và lưu trữ.
Các bạn có thể download bài giảng quản lý số liệu tại đây. Ứng dụng phân tích hồi quy (Regression)20/05/2012 01:22' PM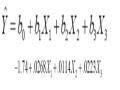 Trong quá trình học tập, nghiên cứu, và làm việc trong lĩnh vực nghiên cứu khoa học các bạn đã từng nghe đến phân tích hồi quy. Vậy hồi quy là gì? Và tại sao chúng ta cần phân tích hồi quy? Bài giảng ứng dụng phân tích hồi quy sẽ trả lời cho các bạn câu hỏi đó và đồng thời giới thiệu với các bạn các bước xây dựng mô hình hồi quy, hồi quy tuyến tính đa biến và hồi quy logic.
Tạo bảng trống/bảng giả cho phân tích số liệu (Dummy tables)20/05/2012 12:12' PM Xin chào các bạn,
Dummy tables là các bảng giả (mock tables) tạo ra trước khi phân tích số liệu, được tạo dựa trên câu hỏi nghiên cứu và kế hoạch phân tích, và giúp định hướng cụ thể các phân tích để trả lời câu hỏi nghiên cứu. Bảng dummy chính là kế hoạch phân tích chi tiết và cũng là công cụ để giúp thảo luận và thống nhất phân tích trong nhóm các nghiên cứu viên, vv. Nội dung bài viết: - Lý do tạo bảng trống - Dummy tables
- Các loại bảng trống
- Tạo bảng trống
- Giới thiệu các loại bảng trống
- Ví dụ tạo các loại bảng trống
| |
